Hierarchical Modelling
Occupational exposure monitoring data are not independent. If you monitored a worker and found their exposures were way above the exposure standard, you would probably be unsurprised to find other workers in the SEG also having elevated exposures. Certain factors, such as the presence of engineering controls, the composition of materials handled, an enclosed work area, etc., that affect all the workers will mean that workers will generally have somewhat similar exposures. Similar exposure groups are similar. Who knew, right?
This idea can be taken another level higher. You might work for a company that has multiple sites. If site A has a maintenance group that consistently has higher exposures than site B’s maintenance group, it’s not unreasonable to expect that the production SEG at A is also worse off than site B’s production SEG. Some sites are just generally worse than others— perhaps due to less funding or older facilities, etc. You could keep going— companies within an industry, industries within a country, etc.
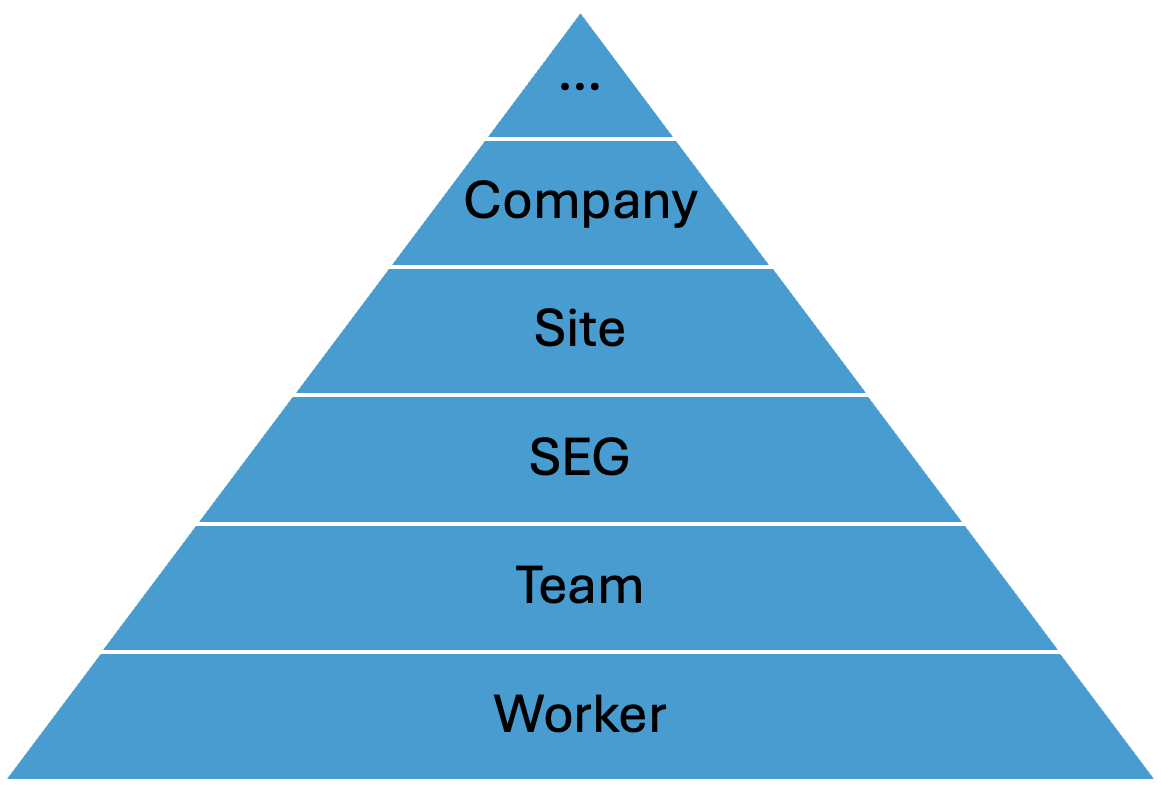
The hierarchy of occupational hygiene data
There is a hierarchy to the data we collect. If we incorporate this hierarchy into our statistical modelling, we can squeeze more information out of our data and even share information between and within the different levels of the hierarchy. This is really helpful as while we may have 100,000s of data at an industry level, we may have little to no data for a given SEG or worker.
Most hygienists will ignore the hierarchy. Say a hygienist went to a site and collected six to ten samples for three different SEGs. The standard approach would be to plug the samples into IHStats or Expostats and assess the 95th percentile (or whichever metric) to an exposure standard, SEG-by-SEG. Thinking of it in reverse, each sample we collect is a draw from an underlying distribution that’s unique to that SEG. This ignores commonality between SEGs from factors that occur at a higher level (e.g., site). As a result, we are left with small sample sizes and noisy estimates of our decision criteria. This approach is referred to as “unpooled” modelling.
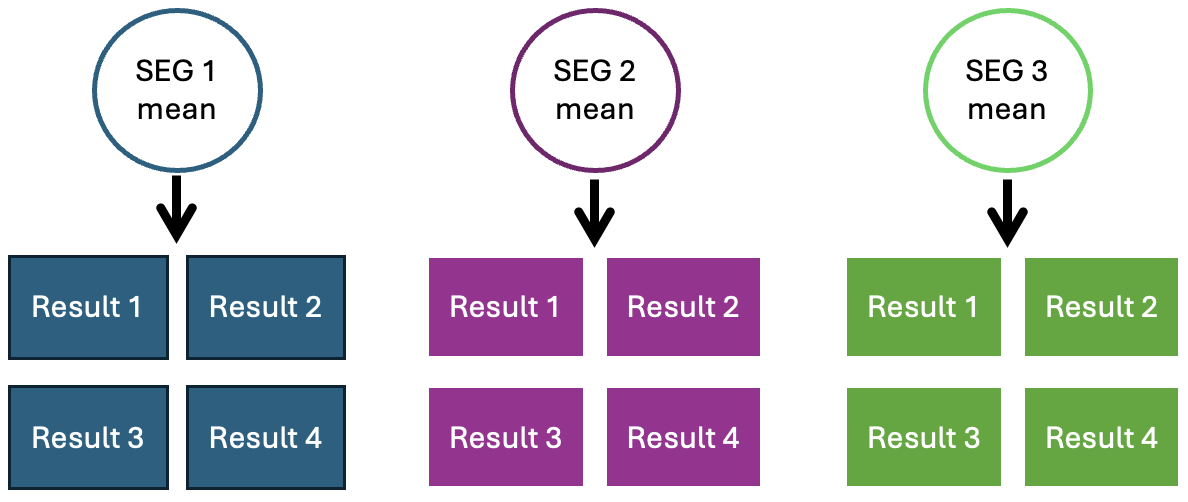
Unpooled data. How analysis is usually done by hygienists.
When the statistics are being performed at a higher level, say analysing an entire industry at once, it’s common to see the exact opposite where the data is “fully pooled”. All of the data are lumped together regardless of the levels of the hierarchy below (e.g. sites, SEGs, workers). It assumes that all results, even from different SEGs or sites, come from one common distribution. This can result in very misleading inferences as it ignores differences between groups at lower levels in the hierarchy. You may end up with high-risk SEGs that are effectively counterbalanced by low-risk SEGs, for example.
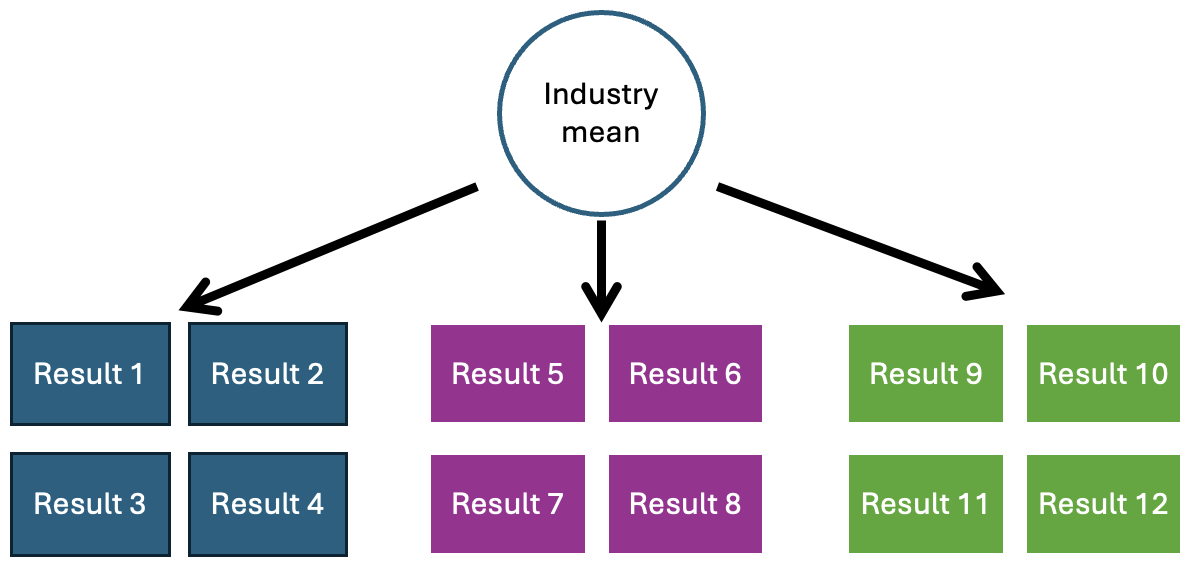
Fully pooled data. How analysis is sometimes done by hygiene researchers.
The solution is to explicitly model the hierarchical nature of the data. This idea falls between the two approaches above and is referred to as ‘partial pooling’. By doing so, you are acknowledging that the data is generated by a specific SEG (or worker) but also that the SEGs of a particular site have some relationship with each other. One of the great benefits of this approach is that there is partial information sharing. Going back to our original example, if you had lots of samples from the maintenance group, this data can partially supplement a production SEG that has very few samples.
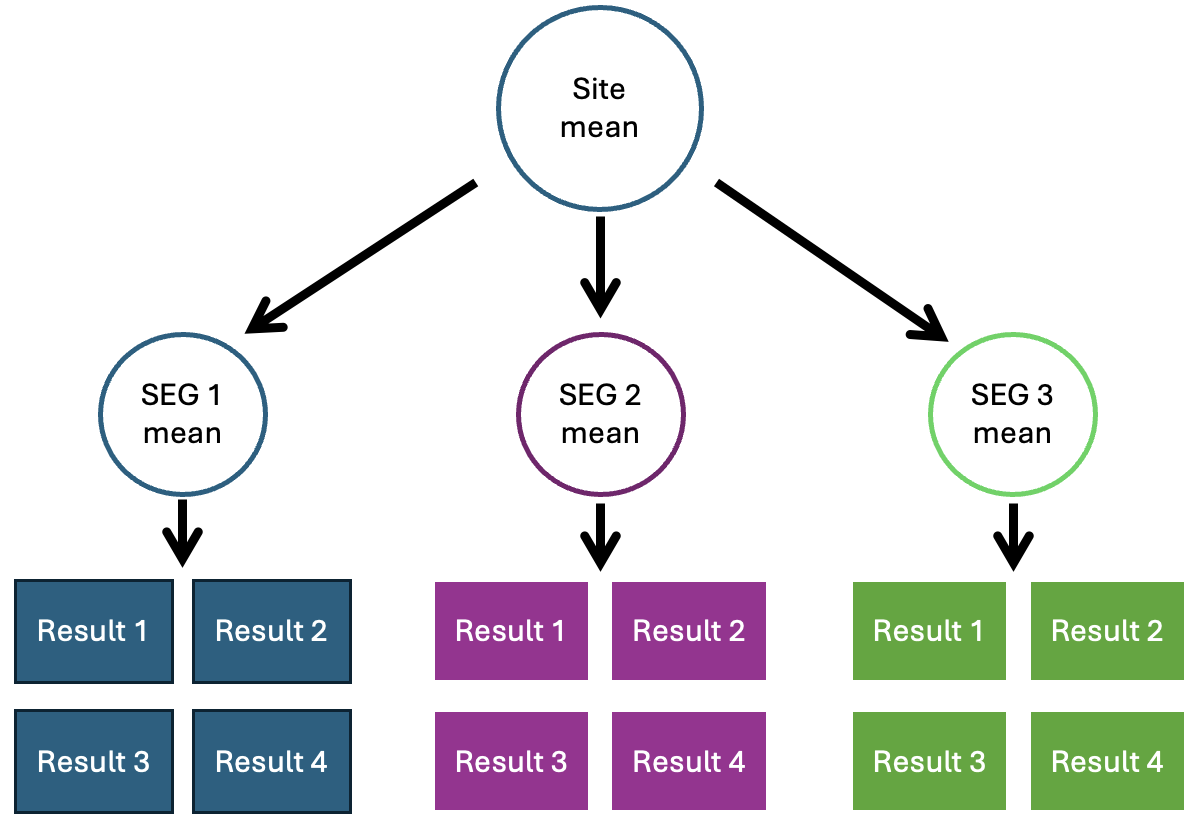
Hierarchical modelling / partial pool. How hygiene data analysis should be done.
The number of levels, and which levels to include is entirely up to you, based on the information you have and what you think is relevant to your model. Best practice is to create multiple different models with varying complexity to compare and see which works best. As with all statistical modelling, the quality of data used affects the quality of the output. You would ideally have consistency on the sampling methodology, and SEG definition method between sites for example.
How to actually perform hierarchical modelling is for a different post (or more likely a proper training session), which I intend to eventually create. There are already tons of free resources - not usually hygiene-focused but still incredibly useful. For example:
https://www.youtube.com/watch?v=zoSk9_5ow3U (lecture)
https://www.youtube.com/watch?v=T1gYvX5c2sM (lecture)
https://xcelab.net/rm/ (textbook)
A.I. was used for punctuation and spell checking. All content was entirely written by a human (me).